AI Topic 3: Moments of Enlightenment in Language Modeling

AI Topic 3: Enlightenment Moments in Language Modeling
Behind several of the most popular generative AIs right now, including ChatGPT and AI for drawing, are ‘Large Language Models (LLM)’. This is also the technical route to AGI. In this talk, let’s talk about why Large Language Models are so powerful.
Let me give you an example. I asked ChatGPT: Can a baseball bat be hidden in a human ear? It said no, because the human ear is very small, and the size and shape of a baseball bat is beyond what the ear can accommodate …… is very organized.
I asked it again: why could the golden rod be hidden in the ear of the Monkey King? It replied that because it was a fictional story, the shape and size of the golden rod could be changed at will ……
These two responses are pretty remarkable if you think about it. Many people say that language models are experience-based and can only output answers based on correlations between words, with no ability to think at all …… But judging from these two Q&As, ChatGPT is capable of thinking.
Who would write an article discussing whether or not a baseball bat can be hidden in a person’s ear?ChatGPT is surely able to give an answer not because it has heard such arguments before, but because it is capable of some reasoning. It considers and knows the relative sizes of baseball bats and ears, and it knows that the Golden Baton and the Monkey King are fictional.
Where did it get all this thinking?
These abilities, in case you didn’t realize, were not designed by the developers.
The developers didn’t require language models to know the size of each object, nor did they set them up to know what was fictional. There’s no end to the list of rules like this one; it’s a dead end.
The language model behind ChatGPT, GPT-3.5, is completely self-taught and touched on these thinking skills. And other capabilities - capabilities you can’t even enumerate. Even the developers can’t say how many thinking abilities it knows.
The main reason language models have such amazing abilities is because they’re big enough.
✵
GPT-3 has 175 billion parameters. meta just released a new language model called LLaMA with 65 billion parameters. google is launching a language model in April 2022 called PaLM with 540 billion parameters; and before that Google came out with a language model with 1.6 trillion parameters. According to OpenAI’s CEO Sam Altman, GPT-4 won’t have many more parameters than GPT-3; but there is speculation that GPT-5 will have 100 times more parameters than GPT-3.
This is something that can only be done today. It used to be that, not to mention arithmetic, the cost of just storing the corpus on which the models were trained was astronomical; in 1981, 1 GB of storage cost $100,000, in 1990 it was down to $9,000, and now it’s just a few cents. You’d have to say that today’s AI science has improved from the past, and computer hardware conditions are the biggest improvement.
- Today we do ‘big’ models. *
Big is different [1]. Of course there is a lot of high level design in language modeling, and in particular the transformer that we’ve mentioned over and over again is one of the most critical architectural techniques, but the main difference is still big. When your model is big enough, the corpus used for training is large enough, and the training takes long enough, some magic happens.
In 2021, several researchers at OpenAI made an unexpected discovery during the training of neural networks [2].
Let me give you an analogy, let’s say you’re teaching a student to give an impromptu speech. He doesn’t know anything, so you find a lot of ready-made material for him to imitate. At the beginning of the training, he can’t even imitate these materials well and stumbles through the sentences. As the training deepens, he can imitate existing speeches very well and rarely makes mistakes. But if you give him a topic he hasn’t practiced before, he still can’t speak well. So you let him keep practicing.
There doesn’t seem to be much point in continuing to practice, because now he can speak well enough to imitate, and he can’t if he’s really improvising. But you don’t budge, you let him practice.
And so you practice and practice, and then one day you realize, to your surprise, that he can speak extemporaneously! Give him a topic and he can make it up and speak on it, and he plays it very well!
The process is shown in the following picture–
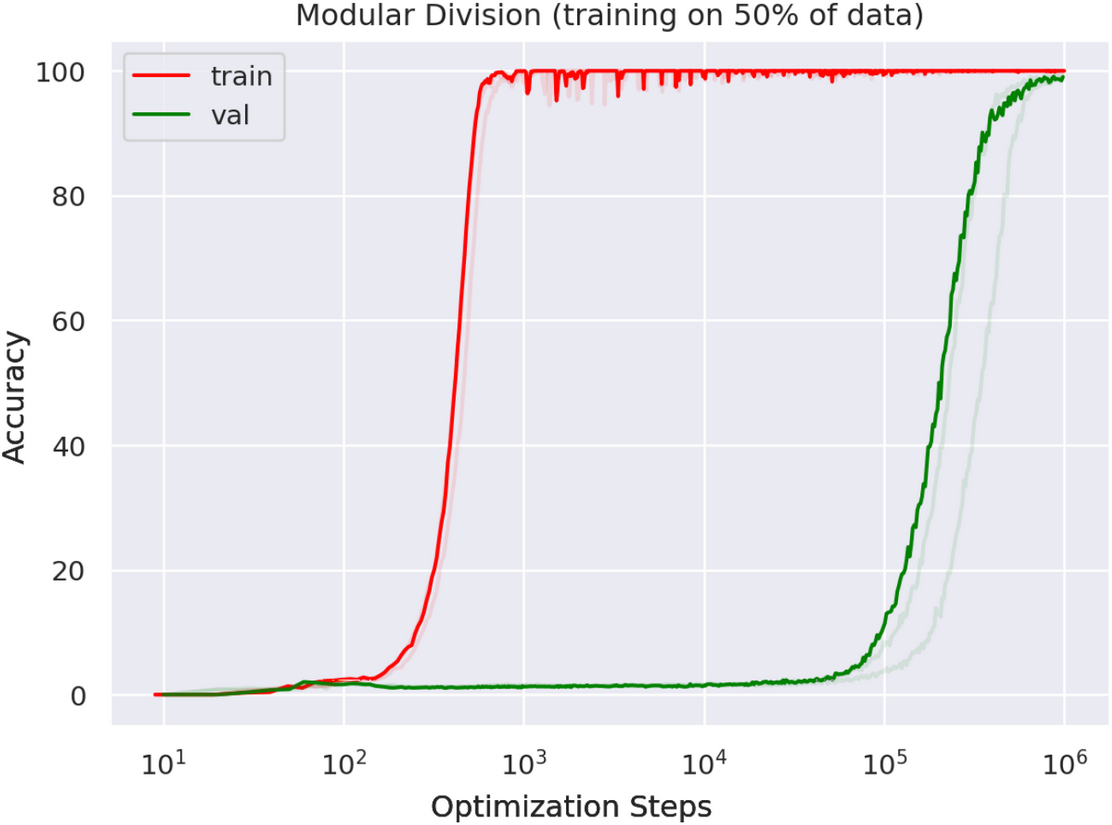
The red curve represents training and the green curve represents generative play. Train to 1,000 or even 10,000 steps, and the model is already performing very well on training questions, but is barely capable of generative questions. By 100,000 steps, the model has done perfectly on training questions and is starting to perform on generative questions. At 1,000,000 steps, the model actually achieves close to 100% accuracy on generative questions.
*This is where quantitative change produces qualitative change. Researchers call this phenomenon “Grokking”. *
✵
Enlightenment, what exactly is happening?
Don’t worry, I’ll give you another example.ChatGPT has a key capability called ‘Few-Shot Learning’, which means that if you give it one or two examples, it will learn what you mean and provide similar output.
For example, I asked ChatGPT to mimic the examples I gave it and come up with some elementary school math problems. My example was “Ming had 3 apples, and his mom gave him 2 apples, how many apples does he have now?” ChatGPT immediately came up with five questions, all in this style - for example, “Little Li has 5 pens, he gave away 3 pens, how many pens are left?”

It’s almost like a pair of couplets. Sample less learning is a key capability that you can use to make ChatGPT do a lot of things for you. So how did this ability come out?
From more parameters and training. Look at this graph below-
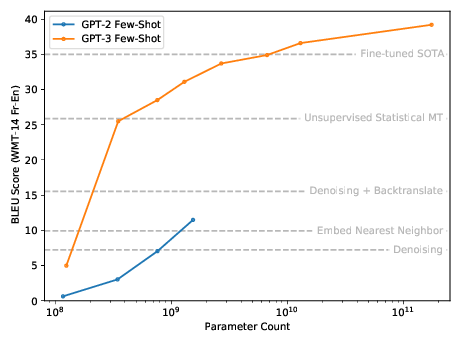
The graph talks about the evolution of the GPT-2 and GPT-3 models. The more parameters there are, the better the ability to learn with fewer samples.
And sample less learning is only one of the capabilities. There are many other capabilities as well: bigger, they come out.
✵
This phenomenon is, in fact, what scientists have been calling “Emergence“ before. Emergence means that when a complex system gets to a certain level of complexity, a phenomenon occurs that goes beyond the simple superposition of the system’s elements and self-organizes. For example, individual ants are stupid, but the colony is very smart; each consumer is free, but the whole market seems to be organized; each neuron is simple, but the brain generates consciousness ……
Large language models, fortunately, also spring up with all sorts of unexpected capabilities.
In August 2022, Google Brain researchers released a paper [3] devoted to some of the emergent capabilities of large language models, including learning with fewer samples, suddenly learning to do addition and subtraction, suddenly being able to do large-scale, multitasking language comprehension, learning to categorize, and more …… And these capabilities only emerge when the model parameters are more than 1000 billion before they emerge -
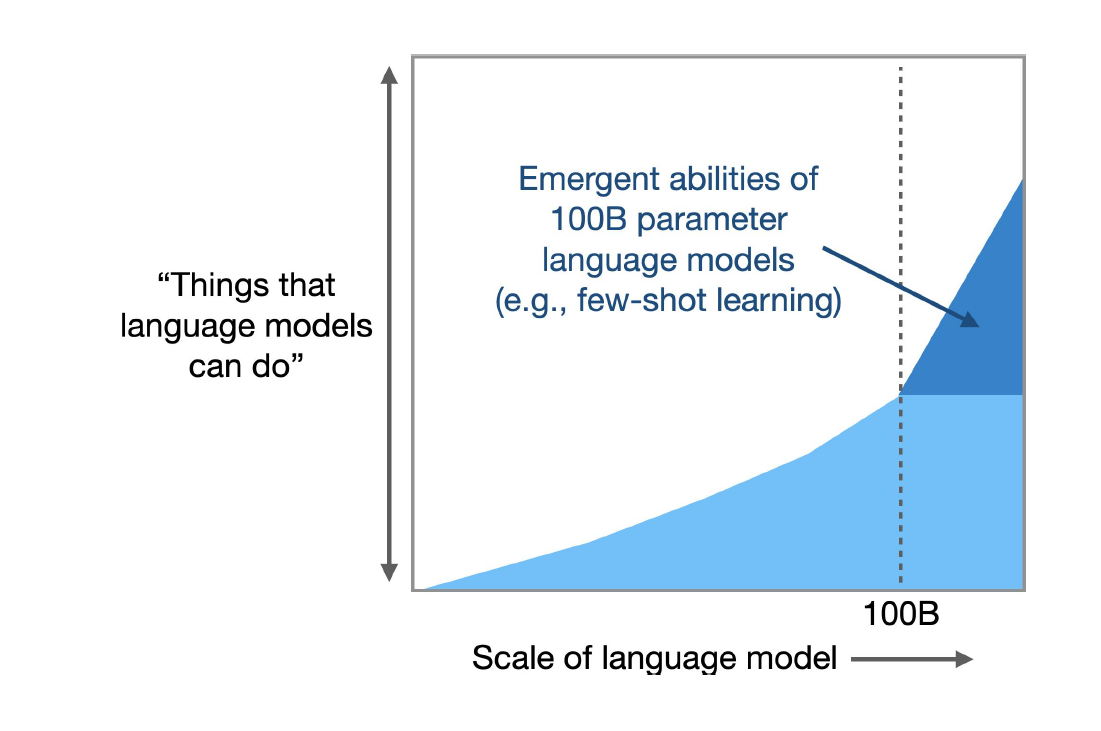
Let me re-emphasize: * The researchers did not deliberately implant these capabilities in the model, they were figured out by the model itself. *
Just as children often grow up beyond their parents’ expectations.
✵
And of course you have to design the model well before you can do that. the transformer architecture is critical in that it allows the model to discover relationships between words-whatever they may be-and isn’t afraid of distance. But the researchers who invented transformer in the first place didn’t expect it to bring so many new capabilities.
In hindsight, the key mechanism for the emergence of new capabilities is called “Chain-of-Thought“ [3].
Simply put, Chain-of-Thought means that when the model hears something, it mumbles to itself, one by one, all the various things it knows about that thing.
For example, if you ask the model to describe “summer”, it will say: “Summer is a sunny season, people can go to the beach to swim and have picnics outdoors ……” and so on.
How do thought chains give language models the ability to think? Maybe it’s something like this. Take, for example, that baseball bat problem we talked about earlier. As soon as the model hears about baseball bats, it tells itself about various aspects of baseball bats, including size; so since your question includes “putting it in the ear”, size is a property worth labeling; and then it does the same thing with the ear …… It compares the size properties of the two. It takes the two properties of size and compares them, finds that they are opposite, and judges that they won’t fit.
As long as the thinking process can be described in language, the language model has the ability to think.
Look again at the following experiment [4]–

Show the model a picture - a still from the Pixar movie Robotech - and ask it which studio created the character pictured. Without a chain of thought, the model will give the wrong answer.
How do you use a chain of thought? You can start by asking the model to describe the picture in detail itself, and it says “There’s a robot holding a Rubik’s Cube in the picture, and this picture is from Robotech, the movie that Pixar made ……”. At this point you simply repeat what it just said and ask it which studio created the character, and it gets it right.
That being the case, as long as we set it up so that the model thinks a bit before answering the question each time, it automatically uses the chain of thought and it has the ability to think.
It has been analyzed [5] that thought chains are likely a byproduct of training the model in programming. We know that the GPT-3 is now available to help programmers program. It does not have a chain of thought when it has not yet been trained in programming. Perhaps the programming training required that the model had to have to keep track of how a feature was implemented from start to finish, had to be able to link two relatively distant things together - such training allowed the model to spontaneously generate chains of thought.
✵
Just on February 27th, Microsoft released a paper describing a new language model of Microsoft’s own called ‘multimodal large language model (MLLM)’, codenamed KOSMOS-1.
What does it mean by multimodal? ChatGPT is that you can only input text to it; multimodal is that you can input pictures, sounds and videos to it. The principle of ChatGPT is to convert all media into language, and then use the language model to process them. The multimodal model can be used to do “look at the pictures and find the pattern” IQ tests like this one–

The previous example of the Robotech stills comes from this paper, demonstrating the chain of thought that goes into looking at pictures. There is this example from the paper, which seems rather amazing to me–

Show a model a diagram that looks like both a duck and a rabbit and ask it what it is. It replies that it is a duck. You say it’s not a duck and guess what it is. It says it looks like a rabbit. You ask it why, and it tells you because there are rabbit ears in the pattern.
Isn’t this thought process exactly like that of a human being?
✵
I see a passage in Xunzi - The Book of Persuasion that can be used to depict the three realms of AI competence exactly-
The first realm is “Accumulation of earth becomes a mountain, and the wind and rain will rise”. * Parameters enough, training to a certain accumulation, you can do something. For example, AlphaGo plays Go.
The second realm is “accumulation of water into an abyss, the dragon is born”. * The model is even bigger to a certain extent, then some unexpected magical functions will emerge. For example, AlphaZero plays Go without following the human routine, and the chain of thoughts of large language models.
The third realm is “Accumulation of goodness and virtue, while the gods are self-possessed and the holy mind is prepared.” * This is AGI now, it generates self-awareness and even has a sense of morality ……
So many people throughout the ages have read Persuasion, and I don’t know how many of them really followed Xunzi’s requirements …… But we now know that the AI definitely listened. You give it study material, it is really learning.
In a nutshell, * because of enlightenment and emergence, AI has now gained the ability to think including reasoning, analogies, learning from fewer samples, and so on. *
We have to rethink all the assumptions we made about AI before - what AI can do is all based on experience, AI can’t really think, AI has no creativity, including the one that “AI can do things that can be expressed in words”, now I’m not sure. I’m not sure anymore.
If AI can reach such a level of thinking through the chain of thought, then how do people think? Is our brain also using the chain of thought, consciously or unconsciously? If so, what is the essential difference between the human brain and AI?
All these questions are calling for brand new answers.
Annotation
[1] https://www.lesswrong.com/posts/pZaPhGg2hmmPwByHc/future-ml-systems-will-be-qualitatively-different
[2] https://mathai-iclr.github.io/papers/papers/MATHAI_29_paper.pdf
[3] https://openreview.net/forum?id=yzkSU5zdwD
[4] https://arxiv.org/pdf/2302.14045.pdf
[5] https://yaofu.notion.site/GPT-3-5-360081d91ec245f29029d37b54573756
Getting to the point
- the three realms of AI capability-
The first realm is “Accumulation of earth becomes a mountain, and the storm rises”. If there are enough parameters and the training reaches a certain accumulation, you can do something.
The second realm is “Accumulating water into an abyss, and a dragon is born”. If the model is big enough, some unexpected functions will emerge.
The third realm is “accumulating goodness and virtue, and the gods are self-aware and the holy mind is ready”. It produces self-awareness and even a sense of morality. - Because of enlightenment and emergence, AI has now gained the ability to think, including reasoning, analogies, learning from fewer samples, and so on.